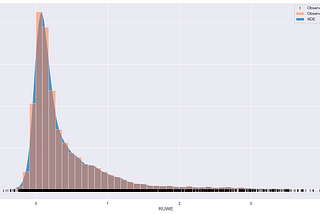
Praveen JayasuriyaIntuition Is A Funny ThingI’m pretty new to Groupoids and Topology. While browsing an introductory chapter in Topology and Groupoids by Robert Brown I noticed the…Dec 24, 2023Dec 24, 2023
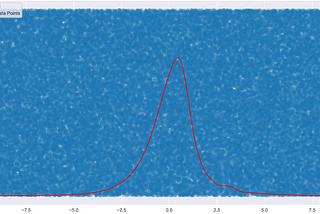
Praveen JayasuriyainAnalytics VidhyaLeast Squares Optimised Fit Using Python— A Basic GuideHow do we choose a reasonable starting point when modeling some data? In the context of statistical inference, this question takes on a…Feb 15, 2021Feb 15, 2021
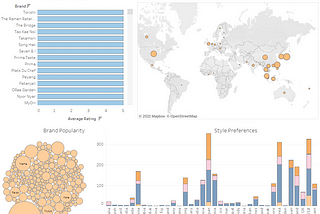
Praveen JayasuriyaTableau Visualisation of The Week — Ramen Around The World!Who doesn’t love ramen? Guess which country eats ramen out of a can?Jan 24, 2021Jan 24, 2021
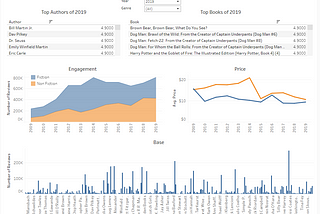
Praveen JayasuriyaTableau Visualisation of The Week —https://public.tableau.com/views/AmazonBestsellers2009-2019/Top50Bestsellers2009-2019?:language=en&:retry=yes&:display_count=y&:origin=viz_s…Jan 18, 2021Jan 18, 2021
Praveen JayasuriyainAnalytics VidhyaGenerating Simulated Data Points That Follow a Give Probability Density FunctionDuring the last couple of weeks, I’ve been simulating some data for a statistical inference project. While the topic of simulating data is…Oct 1, 2020Oct 1, 2020
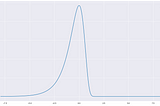
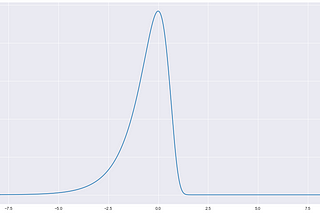
Praveen JayasuriyainAnalytics VidhyaThe Probability Density Function of a Natural LogarithmI’ve been working in the log domain over the last couple of weeks, specifically using the natural logarithm, denoted by “ln”. Life has…Jul 29, 2020Jul 29, 2020
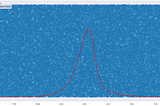
Praveen JayasuriyainAnalytics VidhyaLog Plots, Kernel Density Estimation and Experimental DataI’ve been pretty busy working with some data from an experiment. I’m trying to fit a subset of the data to a model…Jul 6, 2020Jul 6, 2020
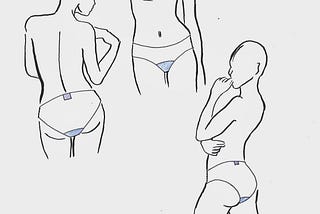
Praveen JayasuriyaStress Incontinence and Period PantiesThis was my second project at MAS Innovations and was extremely rewarding as we were able to build a completely new line of business for…Apr 30, 2020Apr 30, 2020
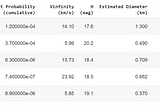
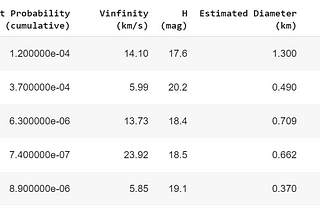
Praveen JayasuriyainAnalytics VidhyaNEAs — Exploring Sentry DataI covered some asteroid and NEA basics in my last post. In this post, we will examine some NEA/NEO data and try and understand some…Feb 7, 2020Feb 7, 2020
Praveen JayasuriyainAnalytics VidhyaNear-Earth Asteroids: An Exploratory AnalysisOur Solar System is a strange place and there’s a lot we don’t know and don’t fully understand. There’s no better way to reflect on this…Feb 7, 2020Feb 7, 2020